AI (LLMs)
Machine Learning
Machine learning is the process of using data, instead of an algorithm, to determine how a model behaves. Tasks such as image recognition, text generation, and many others would be impossible to program manually, since there is an almost infinite number of inputs that would have to be accounted for. Humans perform these tasks using intuition, which is learned from past experience, so what if a computer could do the same?
A machine learning model is a data structure made of parameters (numbers). During the training process, the model is provided with many inputs and examples of what the output should look like, which affects the parameters in the model and changes their values. The result is a model that can mimic the behavior it was trained on.
Deep learning models use a training algorithm called backpropagation. They work by taking an input and turning that input into a list of numbers organized into a multi-dimensional array (tensor). A tensor is then progressively transformed through a sequence of steps (often called layers) until a layer is reached that is considered the output. The result is derived from this final layer.
Transformers
Transformers are prediction models. They take an input (text, audio, images, etc.) and attempt to predict what should come after.
The result of a prediction is a probability distribution: a list of values (for example, a list of words) and the probability of each value being the next word.
To generate text, we can chain multiple predictions together. For example, in the case of text, some text is passed as input to the transformer, which outputs a list of probable words. Then, a random word is chosen from that list and appended to the input of the next execution.
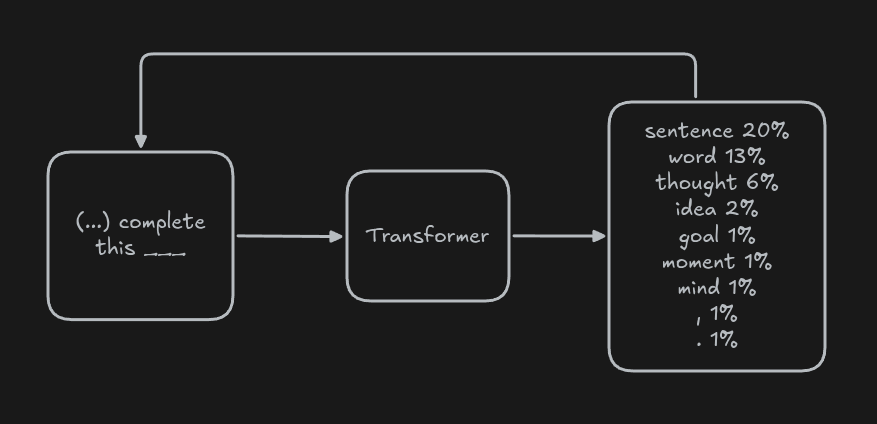
Transformers are great at continuing a given text, so, to turn them into a chatbot, we can provide a template as input, such as this one:
What follows is a conversation between a user and a helpful AI assistant:
User: Explain how LLMs work.
AI Assistant:
The first paragraph establishing a setting of a user talking to a helpful AI assistant is often called a System Prompt.
The user message is passed as the first piece of dialogue, and the final line prompts the transformer to predict what a helpful AI assistant would say in response.
LLMs undergo an additional step of training for this process to work well, but this is the general idea.
Training
A transformer by itself is just a model architecture, or structure. It doesn’t inherently ‘know’ language. To make something useful out of it, transformers are trained on huge amounts of text: books, articles, chat history, documentation, etc. The result of this training process is an LLM, or Large Language Model.
Tokens
LLMs do not process raw words. Instead, they split text into tokens. In the case of text, these can be small pieces of words, punctuation characters, spaces, etc. If the model can process images or audio, then a token could be a piece of the image or a chunk of sound.
For example, the tokenizer for GPT-5 would split the previous paragraph into 62 tokens.

How Transformers Work
First, the input is broken into Tokens. Each token is then associated with a vector (list of numbers) through a process called Embedding, which encodes the ‘meaning’ of that token.
These vectors are then passed on to an Attention block, which updates each vector based on the vectors that came before, giving context to each token (for example, the word ‘model’ could represent a large language model or a fashion model). The attention block is responsible for figuring out which words in context are relevant to update the meaning of other words and how those meanings should be updated.
The updated vectors are then passed through the Perceptron layer, which uses matrix multiplications to ‘ask questions’ of each vector and refine it further. Then, these last two steps are repeated a number of times.
Finally, an operation is performed on the last vector that produces a probability distribution of all possible tokens that can come next.
Embedding
The model has its own vocabulary: a list of the tokens it ‘knows’ (each token representing a word or part of a word).
Each token is represented by a list of numbers (vectors). A list of these vectors forms an Embedding Matrix.
The values of each vector begin as random values, but they are trained with data to represent each token.
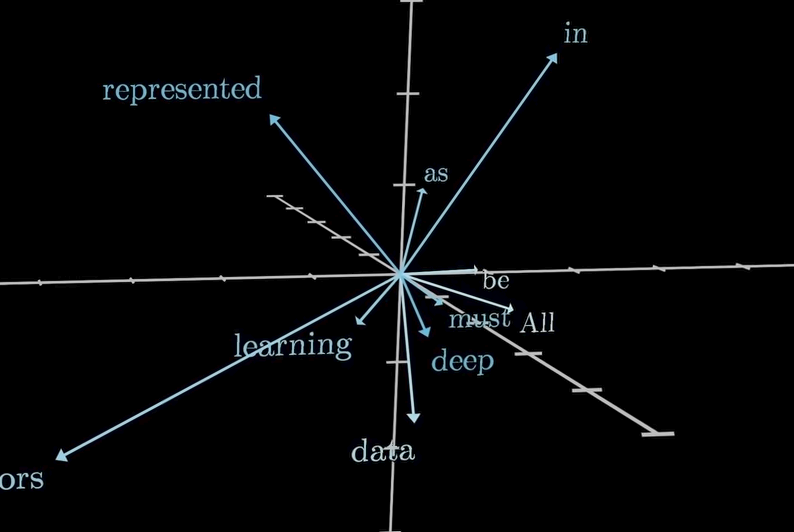
We can think of each vector as coordinates in 3D space, with each token being a point in a multi-dimensional plane. Token vectors tend to be much higher dimensional, since each value in the list is a separate coordinate. GPT-3, for example, had 12,288 dimensions as its embedding space.
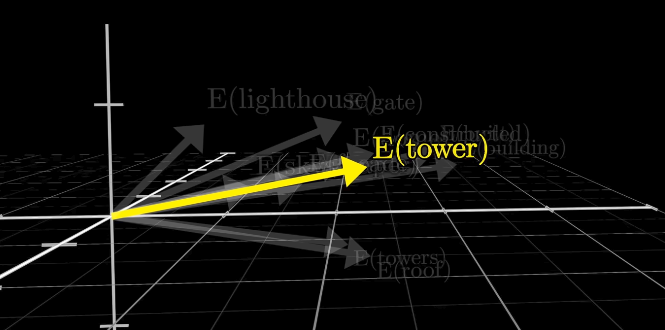
As a model is trained, directions in space gain semantic meaning. For example, searching for the embeddings closest to the tokens representing ’tower’ could result in a list such as towers, gate, building, skyscraper, roof, built, dome, etc., all of which are related to the word tower in some way.
Each direction in space represents something different. For example, the difference between ‘woman’ and ‘man’ is similar to the difference between ’niece’ and ’nephew’, suggesting that at least one dimension conveys gender information. This is useful because, if we wanted to know the female word for nephew, we could add the nephew and woman vectors together, subtract the man vector, and then search for words closest to that point.
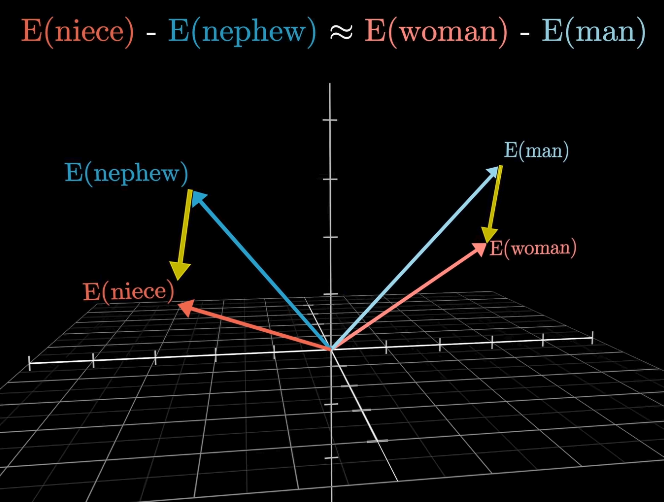
Note: Remember that LLMs do not process words, but rather, tokens. The examples provided use words for ease of understanding, but a real model relates tokens to each other, which may not have any meaning to us humans.
Another useful concept to know is that the dot product of two vectors can be used to measure how well they align. (Multiply all corresponding components and then add the results.)
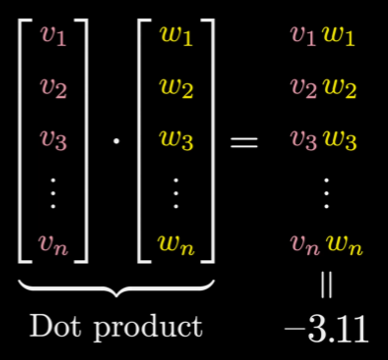
The dot product is positive when vectors point in similar directions, 0 if they are perpendicular, and negative if they point toward opposite directions.
Attention
Attention is the process of encoding context into a vector.
For example, the word ‘bat’ could represent a flying mammal or a sports club. The vector for the word ‘bat’ is always the same at first (encoding the word itself, which would be a token for the model, and its position in context), so to calculate the word that should come next, the surrounding embeddings (tokens in context) pass information to that vector.
To visualize how the attention layer works, we can imagine the following: some nouns may have adjectives that modify their meaning or provide more context. The sentence “A small, orange fruit,” for example, adds the small and orange concepts to the noun fruit. A model, in its parameters, may have a “question” encoded, such as: ‘Are there any adjectives for this noun?’ This question would also be encoded as a vector (list of numbers), which we call a Query. This Query has a smaller number of dimensions compared to an embedding.
To compute a Query, we can take a certain matrix and multiply it by the embedding. This process is then repeated until every token has its own Query. The entries of this matrix are parameters in the model, meaning they are learned from data and difficult to understand ourselves.
Associated with Queries, there are also Key matrices. The process is similar: these matrices are multiplied with each Embedding, generating Keys. Conceptually, these Keys hold the ‘answer’ to each Query. Key matrices are also learned from data and are hard for a human to parse.
A key matches a query when their vectors closely align with each other. To measure how well they align, we can compute the dot product of each possible key-query pair. In the previous fruit example, ‘small’ and ‘orange’ would have a high positive number when measured against ‘fruit’, and unrelated tokens such as ‘A’ would have a negative value instead (in the case of the Query being focused on adjectives). These values range from $(-\infty, \infty)$, but we want them to be mapped from $(0, 1)$ to facilitate future calculations. To do this, we can use the Softmax algorithm and normalize the values. The final set of values is called an Attention Pattern.
This process can be summarized with the following equation:
$$ \mathrm{Attention}(Q, K, V) = \mathrm{softmax}\left(\frac{Q K^{T}}{\sqrt{d_k}}\right) V $$Note: Before applying softmax, the entries representing later tokens influencing earlier ones are set to $-\infty$ in a process called Masking. This is done since many models are trained on all tokens in the training data instead of just the latter to increase efficiency.
The size of the resulting attention pattern is $\text{context size}^2$, which is why context windows are such a bottleneck.
Now that we know which tokens are relevant to other tokens, we need to actually update the embeddings. The value process is responsible for changing a token based on the relevant previous ones. For example, giving ‘fruit’ the property ‘small’.
The most straightforward way to do this is to use a third matrix (Value Matrix), multiply it by the embedding of the first token (‘small’), and produce a Value Vector, which is then added to the embedding of the second token (‘fruit’). This approach is simple, but requires a massive value matrix, and thus isn’t efficient.
A better solution would be to factor the value map as a product of two smaller matrices (“Low rank” transformation).
This attention process is called Self-attention. Some models use different approaches, such as Cross-attention, instead (used by multimodal or translation models). In this latter method, the process is still similar, but Queries and Keys come from different datasets, and masking isn’t applied, since there is no concept of previous or later tokens.
This entire process is referred to as one ‘Head’ of attention. This is because, since there are many types of associations between tokens, a large number of Heads running in parallel are required to encode the full meaning of the context. GPT-3, for example, uses 96 heads per attention block. All of these heads have their own matrices and produce different changes to be applied to each token. To apply changes, we add the outputs of all heads to the embedding of each position. A finished model has many Attention layers. In the case of GPT-3, for example, there are 96 layers, meaning a total of 9,216 distinct heads, resulting in roughly 58b parameters for attention alone, about 1/3 of the model’s weights.
Multi-Layer Perceptrons
MLPs exist between each attention layer and offer more capacity to store information or facts.
First, a sequence of vectors is passed as input to the block, and each individual vector is processed. Then, the result of this operation is a vector of the same size as the original and is added to the input vector.
To process a vector, first, the vector is multiplied by a matrix (model parameters learned from data). We can imagine matrix multiplication as each row of that matrix being its own vector and taking the dot product between each row and the vector being processed. Each row asks questions about the vector and tests its features and concepts. This step often includes adding another vector to the result, called Bias.
While that first operation is linear, language isn’t linear, so a non-linear function is required next. A common approach is to take all negative values and map them to 0, leaving the positive ones unchanged. This function is often called ReLU (Rectified Linear Unit), and closely mimics the behavior of an AND gate. (Modern LLMs may use other non-linear functions, such as GELU.)
Note: The ’neurons’ of a transformer are the values resulting from a Linear step (matrix multiplication), followed by a Non-Linear function, such as ReLU. The neuron is active if the output is positive and inactive if that value is 0.
The final step is to pass the output on to another Linear operation. This reduces the number of dimensions in the output back to the size of the input embedding.
Finally, we add the output to the input embedding, encoding the embedding with useful context and information that was baked into the model’s parameters. This operation happens in parallel for every embedding at the same time.
Unembedding
After the previous two steps (Attention and MLP) are repeated a number of times, the last vector of the final layer is multiplied by another matrix that maps the vector to a list of all tokens known to the model. Once again, softmax is then used to normalize the output, resulting in a list of all tokens and the probability of each one being the next token.
The unembedding matrix is a result of training, with each row representing a token. This is similar to the embedding matrix, but with its order swapped.
Softmax
Softmax turns any list of numbers into a distribution that adds up to 1. The largest values approach 1, and the smallest approach 0. It works by raising $e$ to the power of each number (returning a list of only positive values), then taking the sum of all values and dividing each term by that sum.
$$ \frac{e^{x_0}}{\sum_{n=0}^{N-1} e^{x_n}} $$To adjust a model’s creativity, a constant, temperature ($T$), is used. A higher $T$ makes the output more uniform and allows the result to be more random, thus more creative, while a lower value makes the model stricter and more accurate, closely following its training data. Typical values range from 0.5 to 1.5.
$$ \frac{e^{x_0 / T}}{\sum_{n=0}^{N-1} e^{x_n / T}} $$